What is mainstream music?
Million Songs Dataset Exploration
Jingying Zhou, Yibo Zhu, Yimin Zhang, Ziyue Jin, Ziyue Wu
April 27, 2016
Data and Methodology
Data Integration
We mainly integrated four datasets:
- Million Song Dataset(MSD): A random subset
- User Preference: Echo Nest Tase Profile Data
- Lyics BoW: musiXmatch Dataset
- Genre: Tagtraum Genre Annotations Dataset
We mainly analyze the clusters of songs to extract insights on Mainstream Music and the potential further application.
- we applied sound characteristics(like tempo, loudness, pitch and other 100 features) to get hierarchical clustering of songs
- we used LDA to generate topic model of lyrics, and thus gained clusters of songs based on bag of words description.
- We further used the user playcount data to work out the pairwise "distance" between songs, and thus calculated the used-defined similarity. So that user-defined clusters can be reached by feature selection.
- We visualized and discussed the statistically significant link between lyrics and sound characteristic of songs.
- Our results can be formed into a good song recommendation system, which incorporates user preference, sound characteristics and lyrics preference.
Explore Our Dataset
- Visualization of artists and primary trends in Million Songs Dataset.
- 1. Artists are mainly from North America and Europe.
- 2. In a whole, tempos, loudness and duration increases over time
- 3. Bubble size stands for number of records.
- 4. Color stands for hotness of the artists.
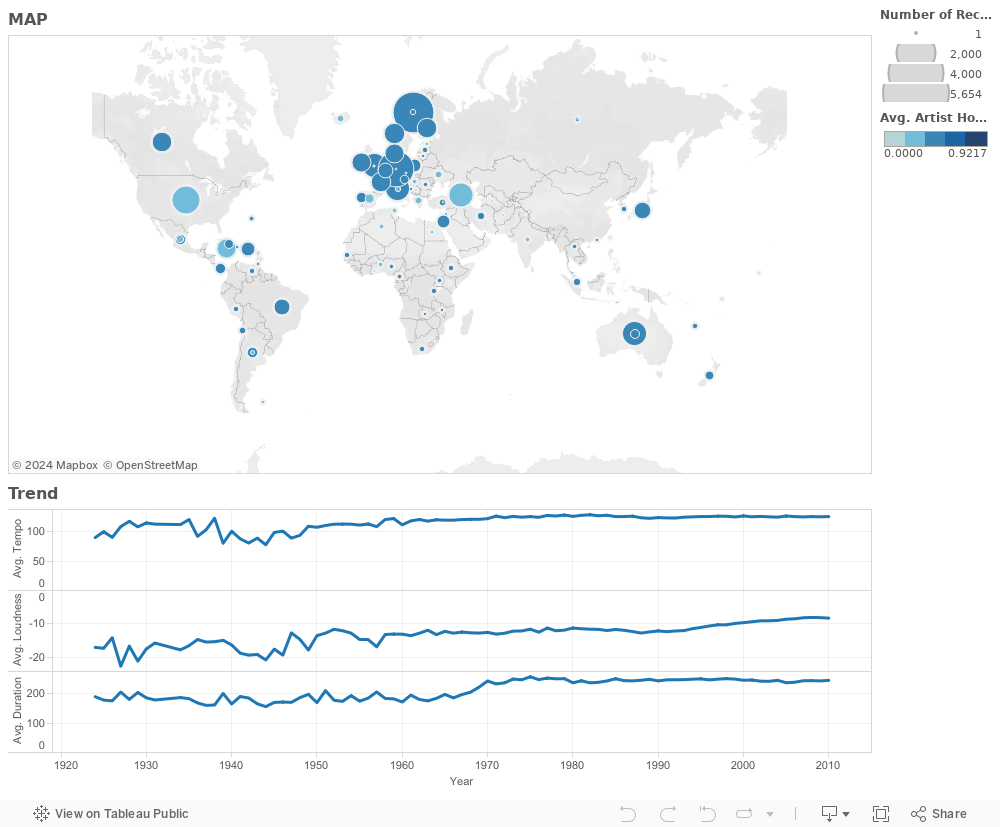
Overview of our songs
- Visualization of Genres
- 1. Except the missing records in recent years, the total amount of songs increased sharply.
- 2. Golden age of rock starts from 1970s (Wiki).
- 3. 1972 the first metal record appeared.
- 4. As an old mainstream music, jazz is becoming less popular.
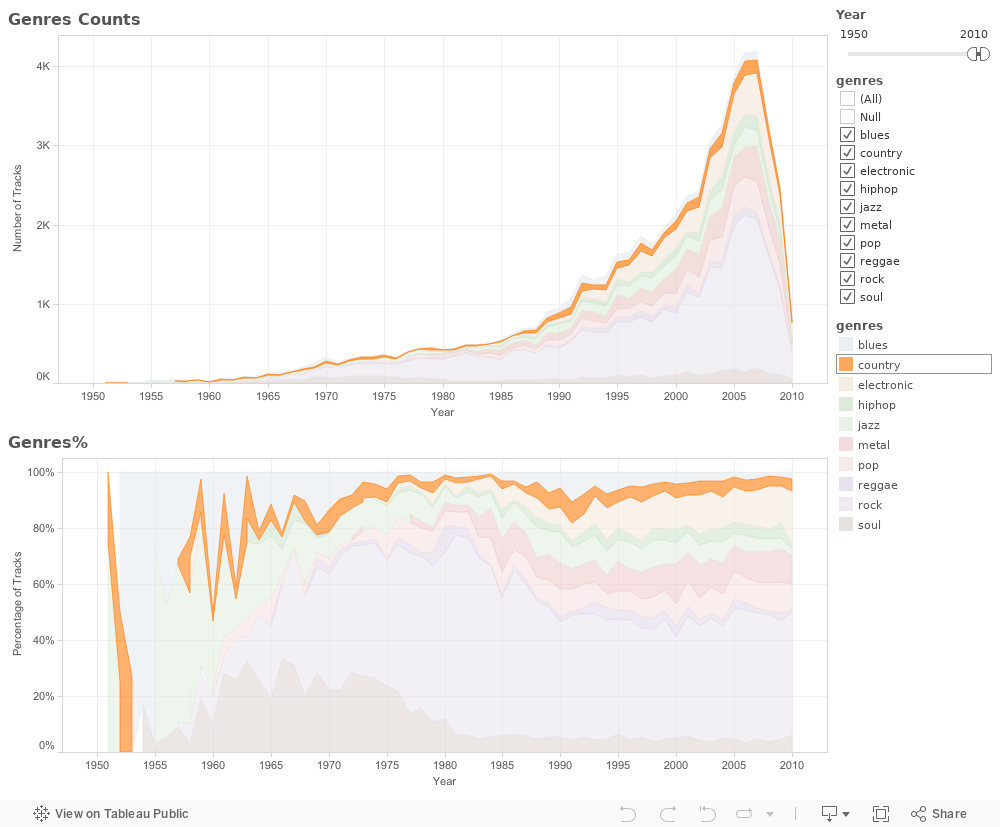
Upon our previous EDA, we're very curious about why mainstream music changes over time. What're the characteristics of a mainstream song? How niche differ from mainstream music? Dose lyrics count in the difference? What is the potential application of a better understanding of Million Song Data Set.
Mainstream?
So here is a questions. Do you think the "Little Apple" is a mainstream song?
How to Define a Mainstream Music?
Sound Features + Lyrics = Music
Part1: Sound Cluster Analysis
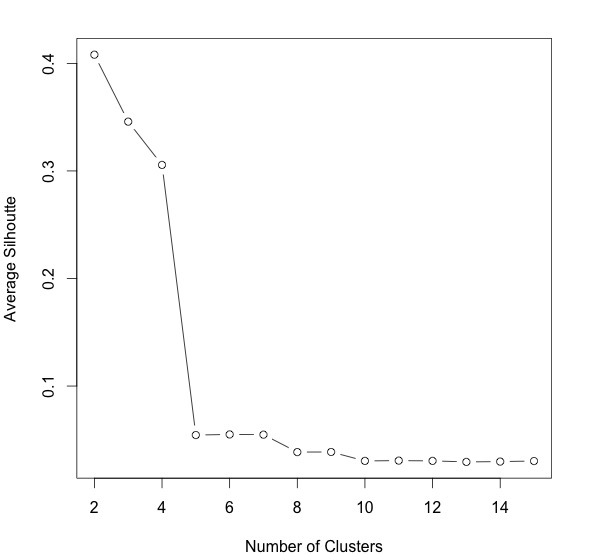
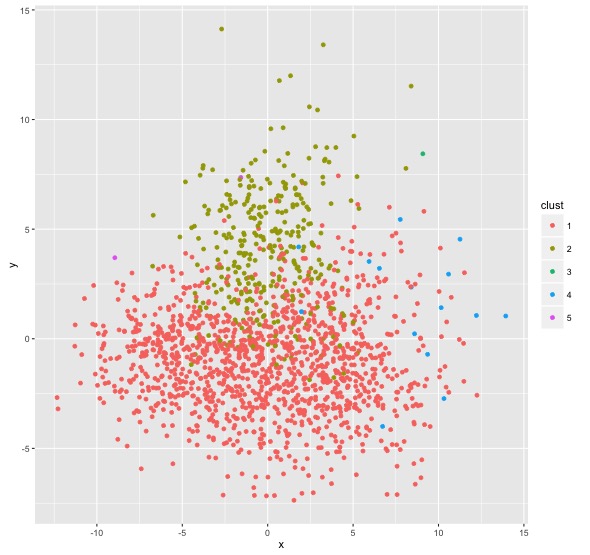
Using all music's features to do hierarchical clustering, and then using silhouette information to determine the appropriate number of clusterings, which is five. Then, proving the results by visualizing data onto dimension reduction map of PCA, using first two principal components. We can see different clusterings are separated in the plot.
Projected on first two dimensions in PCA
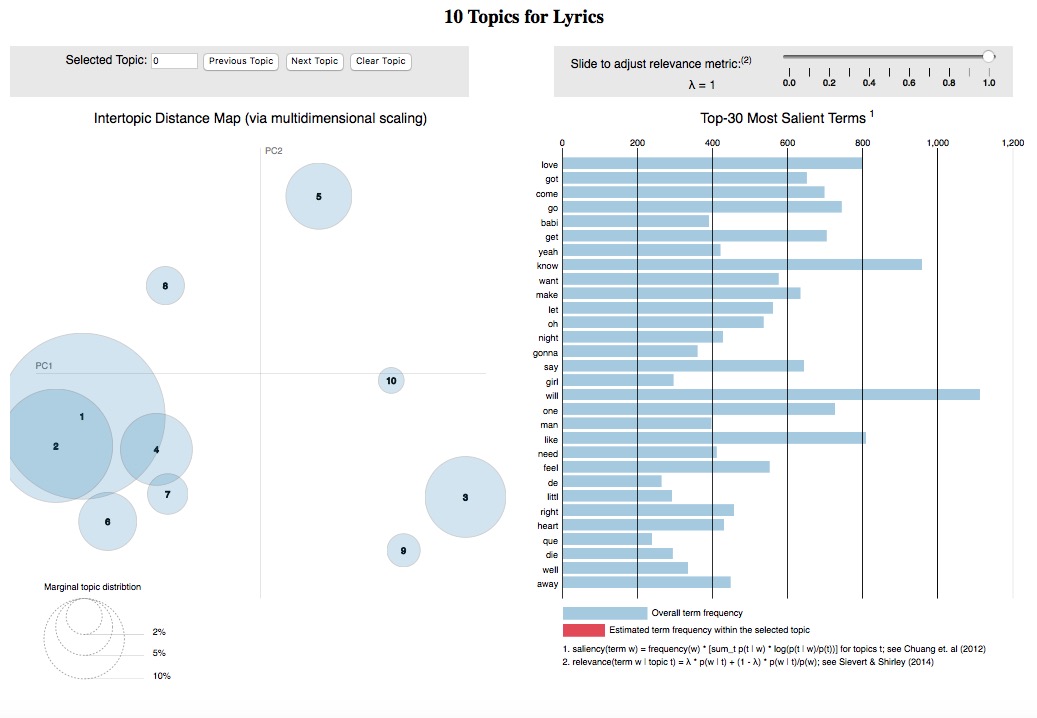
Part2: Lyrics Cluster Analysis
- 1. Used bag of words from each song.
- 2. Choose the number of clusters based on the log likelihood.
- 3. Eventually, we chose 10 topics for clustering and have the following graphs. Click to have more details
- 4. In the coordinate, similar topics tempt to stay closer to each other.
- 5. The size of the bubble stands for the popularity of the topics.
Comparison Between Sound Clusters and lyrics Clusters
How are these two kinds of music clusters related?
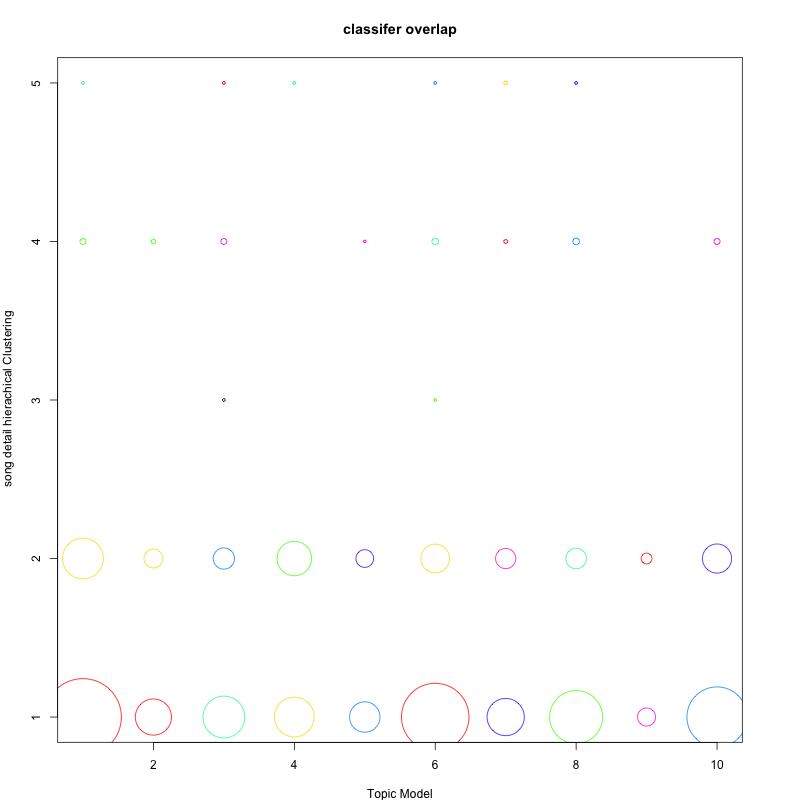
We obtained the Chi-squared test of independence with p-value = 2.2e-16, so we find that lyrics has a strong corelation with sound characteristics.
The Strong coorelation between lyrics and sound can help us dig out insights on mainsteam music. As what we can see in the above bubble figure(classifier overlap), we find topic model and sound hierachical has a dominate overlap in (1,1), (1,6), (1,10). The size-dominated bubbles themselves show they are more prone to be mainstream music, because there are more songs in those clusters which are similar to each other. And this is how we define the mainstream music. Furthermore, the common occurrence means that mainstream music share some common characteristics in sound and lyrics!
Here is a deeper interpretation of mainstream music.
Sound Feature of mainstream music

Lyrics of mainstream music

Verification of mainstream music by adding users information
On the above, we use sound features and lyrics to do the clusters, and then find "mainstream music". But whether they are maintream music? In fact we need user play count info to justify they are. If some songs are similar to a lot of other songs from users' perspective, they are indeed mainstream music. So our goal in this section is to verify that users regard the songs with common words, higher loudness and more tempos as mainsteam music.
Sound Features vs User defined Similarity
User defined similarity monitoring model:
If two songs are listened by one user, we regard this phenomenon as similarity between two songs. But we need to distinguish similarity from popularity. So here is the modelling function:
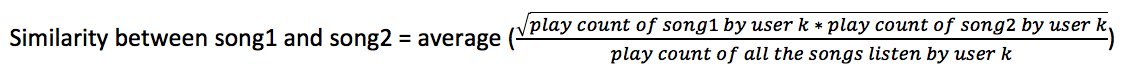
After calculating similarity, we found that similarity matrix is pretty large but sparse. So we used case control to cut down computing size, while keep the representativeness of the original similarity matrix between two songs
Sound Feature Selection Based on User Play Count
We use user play count to select features, and then use selected features to do the hierachical cluster of songs. This result can show the user opionions very well.
LASSO
-
Temporal Feature: 'start_of_fade_out','nbeat','nbar','bt_skw','bt_kts','sc_mn','sc_md'
- melody Feature:'key', 'loudness', , 'ba_kts','timbre_mean9','timbre_median3', 'timbre_median4', 'timbre_median5','timbre_median7', 'timbre_median8', 'timbre_median9','timbre_median12', 'timbre_std4'
- Other: 'year'
Then, I used music features as independent variables and user defined similarity as dependent variables to do lasso regression for feature selection. By setting lambda value by cross validation, we found the best lambda is 0.3. After running lasso regression, we retained 20 features. We interpreted these 20 features as best explaining the user defined dissimilarity between music.
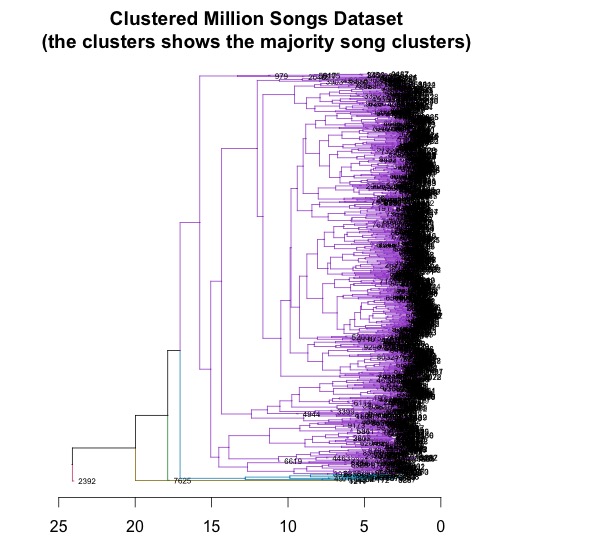
- By using only 20 features selected by lasso regression, we redo hierarchical clustering. After running clustering method, we got a clearer pattern of main stream music and niche music. There is a clearer pattern in the clustering tree plot. Then, we recomputed mean of those features, we saw the result reconfirm mainstream music is faster and louder.
Random Forest:
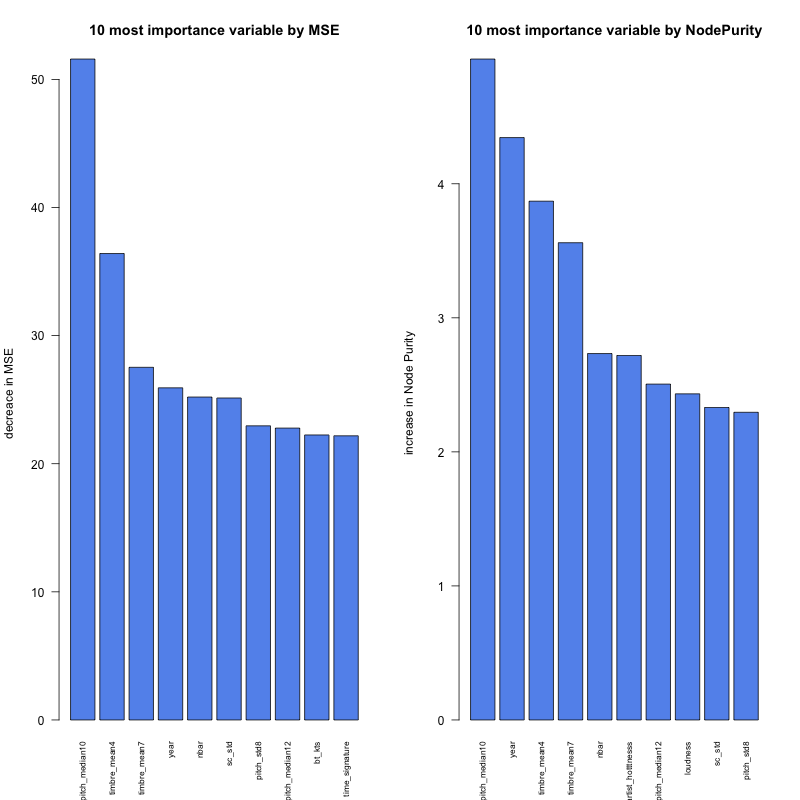
Most of tracks defined in our mainstream formula(louder, faster, common words) are falling into our largest clusters on the above models: (1154/1175), which means those songs are indeed mainsteram music
Conclusion
- Lyrics and Sound feature are highly correlated (p-value = 2.2e-16)
- Mainstream music tends to be lounder and faster compared with niche music
- After adding user defined similarity, the result we had reinforced conslusion 2
- Based on the models we built, we have three dimensions ( sound, lyrics, user defined similarity) to describe a music. Those three dimensions can be used for recommending similar music.